Over the last week I’ve been tossing around some of the granulation scenarios we’ve discussed, and I’ve had a shift of perspective. We have for many months considered Level 2 slices in relation to a main full file slice, onto which they were windows. But now I believe that was a mistake; the Level 2 functionality needs to remain independent, for methodological and market reasons. While this means some changes in the documentation and recommendations, thankfully the schema remains unchanged.
Before I launch into the long story, if you’re just looking for the meeting information, it’s at our usual time (9:00am US Central) and place (Teams Link)!
Sandpiper is founded on statelessness, in that the data available from a Sandpiper node is an immediate snapshot of whatever is current, without history. In this way we can mathematically compare sets of data. That has not (and cannot) change.
Early on, we focused heavily on the Level 1 (full file) functionality, and perhaps this is why we thought of Level 2 as a simply finer division of this full file’s data — not of the source data, but of the full set of data as contained in Sandpiper in a Level 1 slice. We had imagined that an actor would essentially receive Level 2 updates to their Level 1 slice, and would freely choose when to download the full set and when to process updates piecemeal. We also had some vague ideas about reconstituting an updated file using Level 2.
There are two problems with this approach.
First, it means that the Level 2 grains themselves are suddenly turned stateful — because they have to exist in relation to the full file, which is itself a periodic publication and not always up to date. This meant that we were trying to bend the whole foundation of Sandpiper to accommodate the approach.
Second, we’re realizing that this is not at all how people want to use Level 2. If someone has an advanced system that can process updates in real time, why would they also be reconstituting those into a full file? They’re working in a completely different paradigm, no longer in the bulk load-extrapolate-integrate migration chain but in a new much shorter receive-integrate chain. Having to account for the full file in an environment like that would be like buying a pint of soy milk and getting a free gallon of cow milk thrown in. You’re not going to use it because you’re doing something different.
Level 1 is still there as a baseline, checkpoint, fallback, or re-initialization container, but real-time exchange must be able to operate without attempting to keep itself in sync with other datasets.
This also means that the whole root-derivative slice pattern is invalid. There’s no point in slicing up a full file inside Sandpiper when this is not what people would ever do with it. Instead the external tools and systems can handle this in their own domain-specific ways, and insert / delete grains based on those calculations. Sandpiper itself stands free and clear of the content once again.
So with grains now free to move, they are still missing one important piece from the full file: the context.
Effective dates, Vcdb dates, terms of use, whatever, these are all part of the context that the full file gives to its contents. A full file can be thought of not just as a collection of data but also as an envelope with important information written on the outside. This information has to come along with the grains however they are synchronized. Considering this, we came up with three options:
- Take all the important bits and append them to every grain as metadata in the payload
- Upsides: this is a nice way to make sure any processing system only has to look at the grain itself
- Downsides: The same data will be duplicated many times, potentially many millions of times. It adds huge overhead to synchronization, which we already have had to fight to keep lean. And, critically, if the metadata changes on a grain, should it be resynchronized? And how can this be handled to keep all the other grains’ metadata up to date?
- Add the important bits as metadata to every slice that uses them
- Upsides: This keeps the processing local to the container of the grains, which is not too distant. It also doesn’t cost too much in terms of overhead when synchronizing.
- Downsides: Changes to these critical values would need to be tracked by a special routine, and we’d have to come up with a whole set of metadata to add to the schema to allow it. Also, the data is still potentially duplicated, since if I have a pies items slice and a pies assets slice, both with the same content, I have to supply it twice (once on each slice)
- Supply the important bits in a dedicated slice that stores grains, with the grain keys being key values (e.g. “VcdbVersionDate”) and the values themselves as payloads (e.g. “2024-01-27”)
- Upsides: Sandpiper never has to care about the fields or values. It can simply supply a way to handle them agnostically. And since they’re grains, any change to a value (say, an updated effective date) is immediately synchronizable using the exact same methods as any other slice – so context changes can be trapped and acted on. Plus, these values are never duplicated and can’t go stale
- Downsides: New slice type “key-values”, and the complexity of explaining this cleanly
I’ve chosen to head down path #3. It seems clean and simple, and extensible for other uses in the future too.
I’ve updated the documentation in the development branch of our github repository to remove the root slice section and replace it with the context slice. This week I want to talk about it with you all and make sure this makes sense.
Here’s the updated doc:
The Context Slice
A Level 1 slice contains a full file that can only be communicated in full. Often these files contain important contextual information that applies to the rest of the information in the file — for example, validity periods, reference database versions, and so on.
However, at Level 2, this information may not be present in the individual pieces being granulated. In the classic Level 1 scenario it’s assumed that, by virtue of being in the full file (as a header, a footer, preamble, etc.), this information will be used by a processing system for all elements inside. When we break the information up, we lose the context. Sandpiper solves this problem with a special slice: The Context Slice.
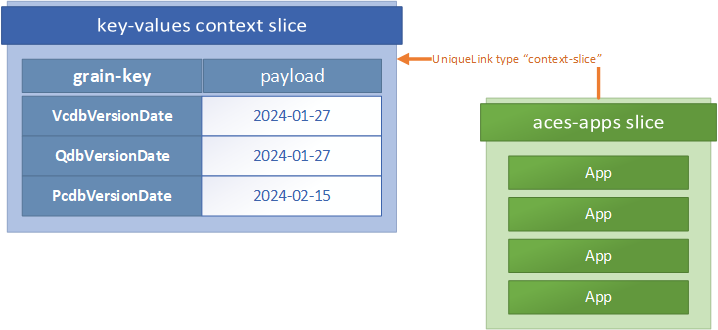
In the context slice pattern, we define a Level 2 slice with slice-type “key-values”, a format that assumes all grain keys are the name of a field, attribute, or property, and the payload of the grains inside the slice contains the values associated with that key*. Then, any slice can indicate that it inherits that context with a unique link pointing to the context slice’s UUID (link type “context-slice”).
* Note that this is still a proper slice — with UUIDs that reflect the unique state of the content within. So a change to any of the key values will necessitate a new grain UUID, even if the grain key does not change. In this way context can also be synchronized using the same methods as any other Sandpiper slice
